A tale about object encryption

Encryption is difficult, it shouldn’t be, but it always seems to be a challenge. While something is difficult to do, its adoption is going to be very slow.
At Wealth Wizards, we are keen to ensure that the data we store is safe and secure, this led to the decision to do row level encryption within our databases in order to separate access to the database from access to the data — defence in depth. But this level of encryption does not make using the data very easy.
This is a little tale about encrypting objects and managing their encryption keys.
Basic encryption
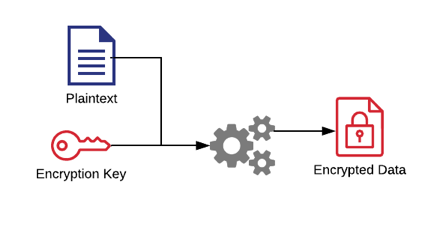
To encrypt an object, you have the plaintext object that you want to encrypt and an encryption key that you pass through an encryption algorithm to produce an encrypted version of the object.
To decrypt you use the encrypted data with the encryption key to run back through the encryption algorithm to produce the plaintext object.
This is pretty straightforward.
Initialisation vector (IV)
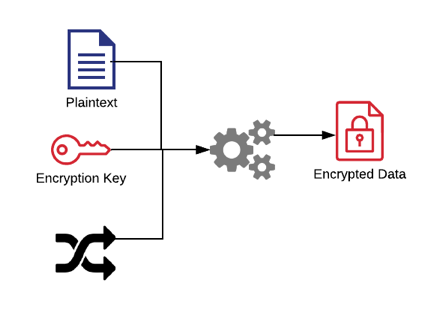
To make your encryption more secure you should use an initialisation vector, it should be random or pseudo random and its use should be limited, for example; one IV per record in a database.
Using an IV means that if the same text is encrypted with the same key then you get a different output from the encryption algorithm, this makes it more difficult for an attacker to identify patterns in the encrypted data.
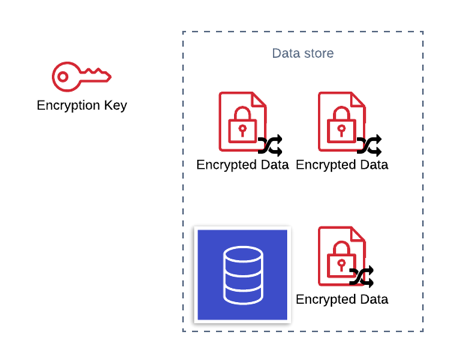
The IV is not a secret which means you can store the IV in the database against the encrypted data that uses it. However, the encryption key should not be stored with the encrypted data, instead should be kept somewhere secure.
A compromised key
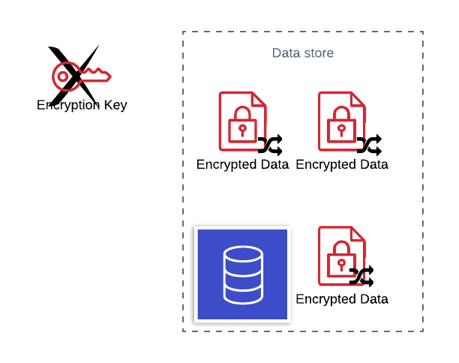
Using this mechanism to encrypt can leave your database records vulnerable, if the encryption key is compromised by an attacker then all records in that database can be decrypted by the attacker.
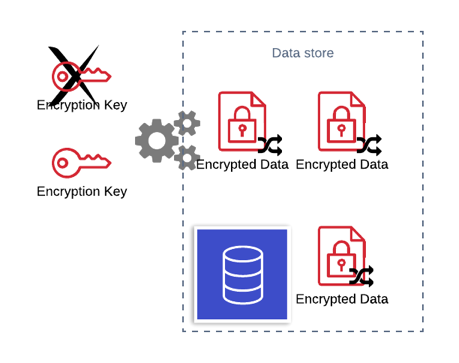
To mitigate this, all data encrypted with that encryption key should be re-encrypted with a new encryption key. In a simple implementation this would mean that the services access the data would have to be taken offline while the re-keying is applied.
One way to get around this problem is to implement encryption key versioning and embed information about the version of the key in the encrypted object. This would allow you to encrypt new data with the new version of the key and still decrypt data that used an old key. Re-keying the encrypted data could be done online as long as any service using the data has all versions of the key.
However, now we have a lot of our own encryption code that we have to maintain
Encryption as a service
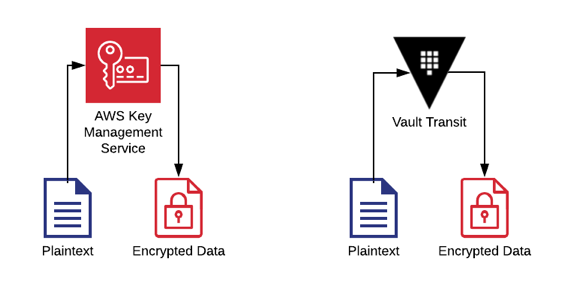
Encryption services allow the plaintext object is passed to them requesting that’s it’s encrypted with a specific key and the service returns the encrypted data to be used.
Hashicorp Vault’s transit secrets engine and Amazon Web Services’ Key Management Service (KMS) are examples of encryption as a service. Your mobile phone’s security chip also provides this functionality.
As well as not having to manage our own encryption code base, the main benefit is that the encryption keys never leave the secure environment, which means it’s very difficult for them to be leaked. Instead, the are protected with authentication and authorisation processes which allows services to be granted access in a secure way.
They offer built in key rotation and will automatically use the newest key when encrypting (or re-encrypting) an object, whilst data encrypted with an old key can still be decrypted.
On top of this they offer a “rekey” function that allows an encrypted payload to be re-encrypted with a newer key without having access to the plaintext version.
However, there are limitations; they normally have a hard limit to the size of object that they can encrypt, and even if they didn’t that can be a lot of data to pass over a network connection.
If you are doing granular levels of encryption, like row-level, you could be making many requests to the encryption service for each transaction.
Both of these could potentially make your system slow.
Envelope encryption
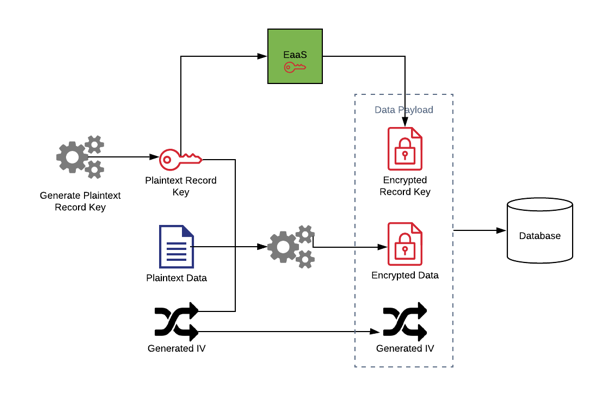
Envelope encryption combines both these methods to provide a scalable, secure solution to encrypting data.
Rather than using the service to encrypt all our data, a record encryption key is generated for each object that is to be stored. The plaintext object is encrypted with that record encryption key and an IV.
The record encryption key we just used on the object is itself encrypted by the encryption service to provide an encrypted record key. Then we store the encrypted record key, the encrypted data and the IV as a record in our database (or other storage, e.g. a queue).
To decrypt, we use the encryption service to decrypt the record encryption key, which we can then use in turn with the IV to recreate the plaintext object.
This combines the benefits of the other encryption mechanisms; we can protect our encryption keys and manage their access securely, whilst avoiding too many requests to the encryption service.
Using a unique encryption key for each record means that if any one of them gets leaked, then only that record is exposed. That key can be cached while a service is actively reading and writing that record to speed up the encryption process and can be easily rotated when writing a record.
Summary
We’ve been doing row level encryption for a while now and it’s caused us some headaches. Developing software that is storing sensitive information becomes difficult when trying to do it securely, and, rightly or wrongly, the effort to do so is always balanced against business functionality. So, any encryption mechanism that can be securely controlled and yet is easy to work with must be the way forward.
After looking into using AWS KMS more in our system, it became apparent that AWS services (e.g. S3, DynamoDB) that provide encryption with KMS use envelop encryption to store their objects: https://aws.amazon.com/kms/faqs/
Exploring these encryption mechanisms has lead us to build confidence in using the AWS provided encryption as a service (KMS) to protect our data. Access is tightly controlled with policies on the KMS keys as well as the data sources like S3, to ensure that they are not accessed from outside our controlled environments.
Some encryption is good, easy encryption is better.